This repository contains the ALiBi code and models for our paper Train Short, Test Long. This file explains how to run our experiments on the WikiText-103 dataset. Read the paper here.
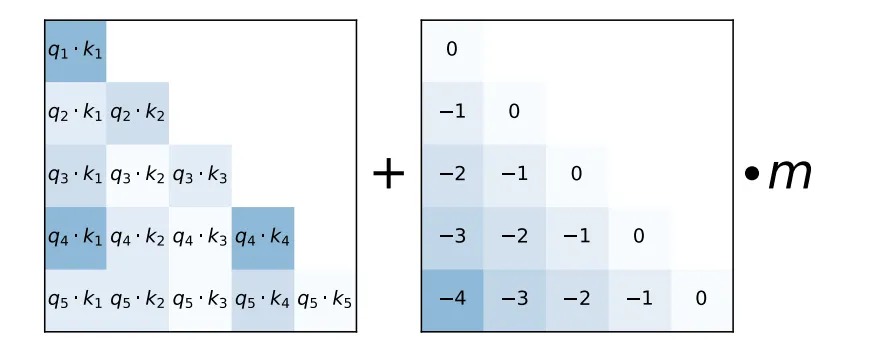
Attention with Linear Biases (ALiBi) is very simple! Instead of adding position embeddings at the bottom of the transformer stack (which we don't) we add a linear bias to each attention score, as depicted in the figure above. The 'm' hyperparam is head-specific and is not learned- it is set at the beginning of training. We have a function that automatically generates these m values given the number of heads in the model.
ALiBi allows the model to be trained on, for example, 1024 tokens, and then do inference on 2048 (or much more) tokens without any finetuning. It's also able to improve performance, even when not extrapolating, in lower resource language modeling settings.
Source :https://github.com/ofirpress/attention_with_linear_biases